Nested specifications
Module. You fill in the abstract methods to implement your algorithm. Sub-classing from Module
ConfigSource, which will be your connection to configuration parameters and TimeSource, which will be your source for time informationModule class is as follows,
class Module { public: // you must define these virtual bool initialize(ConfigSource* config, utils::SymbolTable* table); virtual bool run(); // you may define these virtual bool initializeDisplay(ConfigSource*); virtual bool display(); virtual bool displayIdle(); };
You must implement an initialize function to read in all of your module parameters and set up your module reconfigurable interfaces, and you must implement a run method which represents one cycle of your algorithm. The other methods are for implementing development displays. If you keep your displays separate from your algorithm, it will make your algorithm easier to port in the future, as display code can be very specific to a particular graphics library, while the code in the run method should be specific only to your algorithm.
One of the key things that the Module class does for you is run your module's life cycle. That life cycle can be paraphrased with the following simplified pseudo-code:
Set up ConfigSource and TimeSource if (!initialize() || !initializeDisplay()) exit(); while (running) { if (paused) { if (!displayIdle()) exit(); continue; } if (!run()) exit(); Do administrative stuff if (time_for_display) if (!display()) break; } exit();
After setting up the ConfigSource and TimeSource and calling your initialization routines, the module sits in a loop while a special variable called running is set. If it is paused, it does the minimal display updates you define in your displayIdle method. When it is not paused, it calls your run method. It then takes care of some administrative issues, and if it is time to display, it invokes your display method.
UTILS_DIR: The directory where the ModUtils package is installed.INSTALL_DIR: The directory where your module binary, libraries, and headers will be installed. This is most often identical to UTILS_DIR, but shouldn't need to be. (There may be unfound bugs where developers have assumed they are the same, though).PLATFORM: Defines the platform which we are compiling for. If you do not know this value, just run the script ModUtils/configaux/config.guess and set it based on the result.We provide two makefile fragements that you include into your module Makefile that allow you to specify a full module makefile in just a few lines. In this section we will simply go over the standard pattern for making a module, but these same makefile fragments can be used to build libraries, interfaces, and hierarchies of directorys using different parameterizations, and you can learn more about the details of that in the makefiledescription section".
The basic module Makefile should look something like this,
SRC_MODULE = PushBroom
include ${UTILS_DIR}/include/maketools/MakeDefs
TARGET = wander
TARGET_OBJS = wander.o
TARGET_LIBS = -lVehPose
EXTRA_INC_DIRS =
EXTRA_DEFS =
EXTRA_TARGET_LIBS =
EXTRA_DEPENDS =
include ${UTILS_DIR}/include/maketools/MakeTail
In this example, we start by setting the module name to PushBroom with
SRC_MODULE = PushBroom
Then we include the first half of the pair of critical makefile fragments:
include ${UTILS_DIR}/include/maketools/MakeDefs
$UTILS_DIR/include/maketools/MakeDefs to be included in your final makefile. This particular fragment sets up many of the variables and rules that will be finalized in the second fragment.Then, you define the target, which is the name of the program that your module code will compile to, so
TARGET = wander
wander.Then, you define the list of object files that will go into making this executable:
TARGET_OBJS = wander.o
wander.o, but you could have any number of .o files here.
Next you list all of the "local" libraries you will use. Local libraries are ones which have makefile fragments defined in $UTILS_DIR/include/<library name>/<library name.mk> . Usually this is the list of reconfigurable interface libraries you will be using.
TARGET_LIBS = -lVehPose
.mk files.Often, that will be all you need to set up a makefile for a module, but there are some common "extra" parameters having to do with linking and compiling your target module with external libraries:
EXTRA_INC_DIRS: If you are using external libraries, you will often need to specify a list of directories to look in for include files when compiling your code. You enter in the necessary -IDirectory entries with this option EXTRA_DEFS: In addition, when using external libraries you may have to specify extra definitions for proper compilation. Do that with this parameter EXTRA_TARGET_LIBS: You specify the extra libraries you are linking with via this option EXTRA_DEPENDS: If you want your target to be relinked if an external library or file changes, just put that external library or file in this option. This will cause a new makefile "dependency" on the files listed.include ${UTILS_DIR}/include/maketools/MakeTail
#include <ConfigSource/Module.h> // for modules #include <ConfigSource/ConfigSource.h> // for getting config vars #include <RoadSource/RoadSource.h> // we will be getting Road information class RoadCollectModule : public Module { // define my subclass private: RoadSource* _road_source; // holds the road interface bool _exit_on_no_data; // true if error in getting data causes exit std::vector<RoadPoint> _points; // storage for getting the road points public: // constructor: takes command line argument // superclass also takes canonical "name" of this module RoadCollectModule(const char* spec) : Module("RoadCollector", spec) {} virtual bool initialize(ConfigSource* config, utils::SymbolTable* table); virtual bool run(); virtual bool initializeDisplay(ConfigSource* config, utils::SymbolTable* table); virtual bool display(); }; MODULE_MAIN(road_collect, RoadCollectModule);
Some quick notes about implementing your module that you should remember:
false if the module should exit and true if it should continue. display method shows the most recent results, in this case, cached in the _points class member variable. run and the display methods may not be strictly interleaved. To avoid thrashing the display the display method is set up to be called at most at 30Hz, i.e., if your run method is running at 100Hz, your display method will only be called at most every third time. run method represents one iteration of an algorithm, which means that any "state" that must be maintained between algorithm iterations should be stored in class member variables. run invocations. Remember that, in essense, class member variables can be considered by you, the module implementer, as guilt free globals. _ as a prefix for all member variables (such as _road_source or _road). This gives a good ongoing visual clue as to what is a class member variable and what is a local variable. This becomes very important as your module and its methods become larger and more complex.main routine. This is because for a module, we have found that the main hardly ever changes. Basically it just
module as the appropriate sub-class of Module with the command line argument module->mainLoop() until it exits module
MODULE_MAIN(road_collect, RoadCollectModule);
The first argument, in this case road_collect, is the module "nickname." The major impact of the nickname is that by default we will be reading configuration informatoin from nickname.cfg (road_collect.cfg in our example). The second argument is your Module sub-class name, in our example this is RoadCollectModule. This macro is not just for convenience: it also allows us to port modules to esoteric operating systems such as VxWorks which eliminate the main entry point entirely.
Module super-class does for you is set up the configuration source. The configuration source is a subclass of ConfigSource and represents an abstract interface to a database of named values. Most module developers can consider it a local parameter file, but it really holds and abstracts much of the architectural glue that holds systems together.
./module mymodule.cfg
says to start the module with a file-based configuration source loaded from the file mymodule.cfg. With no arguments, as previously stated, the parameter file defaults to the module 'nickname' with .cfg appended to the end.
You can specify the configuration file with an absolute path, but if you give no absolute path, the configuration file will be searched for in the directories defined by the following environment variables in the following order:
$DATA_DIR $LOCAL_CONFIG_DIR $CONFIG_DIR $HOME (the default home directory variable)$DATA_PATH with a list of colon separated directories, then the configuration source will search in those directories and ignore all of the other environment variables. For example if you set DATA_PATH to ".:~/master_config:~/other_config", then the configuration file will be searched for in the current directory, then in ~/master_config, and finally in ~/other_config.#define's or internally fixed parameters, as this will give you much better control over tweaking the module's operation during the debugging phase.The syntax of a configuration file is vaguely reminiscent of C structures, but has been specialized for the demands of configuration specification.
int (integers)float (single precision floating point numbers)double (double precision floating point numbers)bool (boolean values such as true/false, 0/1)char (single characters)string (standard C strings)In a configuration file, their definition would look something lie this,
int param1 = 1; param2 = hello; string param3 = "Quoted string";
Note param1 and param3 have type identifiers while param2 does not. Omitting the type identifier in the means that the configuration element is not assigned a type until it is read by the C++ code. In the meantime, param2 has the string "hello" stored, unparsed. While it may be convenient to leave out the type identifier in the configuration file (to save your fingers some typing), in the normal course of operation we suggest you use type identifiers so that typos are more likely to be caught at parse time, when all of the configuration file information, such as line numbers, is available rather than caught at evaluation time when much of this information has been lost.
The actual module initialization code for this example should look somethinhg like,
bool FooModule::initialize(ConfigSource* config, utils::SymbolTable* globals) { _param1 = config->getInt("param1", 5); // results in 1 (5, the default, is overridden) _param2 = config->getString("param2"); // results in hello as param2 is now parsed as a string _extra_params = config->getFloat("extra", 3.0); // results in default, 3.0 return true; }
The pattern when accessing simple types is very consistent. Each type has an access method, i.e., getInt for int, getString for string, etc. Each method takes the name of the parameter and a default if the parameter is not there. The methods will try and convert parameters if possible, i.e., if you use getDouble on an element declared as an int or float, the result will be converted to a double for you.
int array[3] = 1 2 3; string sarray[2] = hello; # syntax error double darray = 5.0 6.2 7.3 4.3 # size unnecessary
Note hat # is the comment character. In your C++ code you will can access arrays like this,
int array[10]; int num_vals = config->getInts("array", array, 10); const char* sarray[3]; int num_strs = config->getStrings("sarray", sarray, 3);
The size specification in the configuration file is unnecessary. It is primarily used as a redundant method for catching errors early. If you know you are creating a homogeneous matrix with 16 elements, it is useful to put this size in the configuration file in order to catch cut-and-paste errors on the number of elements.
If it is important to you do get all of the elements of an array, and do not want to depend on a fixed upper limit like this example, you can access the number of values read in via the numValues method, create an array using new, do something with the values, and then get rid of the array with delete.
int num_vals = config->numValues("array"); int* array = new int[num_vals]; config->getInts("array", array, num_vals); . . delete [] array;
structure like this,
struct structure { int sub1 = 5; }
And then access the elements of that structure using the structure name prepended to the variable name with a period.
int sub1 = config->getInt("structure.sub1", 10); // overridden by 5 in the file const char* sub1 = config->getString("structure.sub_str", "def"); // returns the default, def
In addition to using the dotted names, there exists advanced "whole structure" access through the utils::ConfigFile class, which is the class underlying the configuration source.
utils::ConfigFile structure; if (config->getStruct("structure", structure)) { int sub1 = structure.getInt("sub1", 10); const char* sub1 = structure.getString("sub_str", "def"); }
Syntax for the ConfigSource class is actually derived from the utils::ConfigFile class, so the accessing methods of both classes work the same way.
structArray type), but the one that works best uses the following code idiom.First, in your configuration file, have an array of strings which are structure names,
string structures = Structure1 Structure3;
followed by the list of possible structures,
struct Structure1 { } struct Structure2 { } struct Structure3 { }
Note that this allows us to quickly select and unslect which structures to use and what order to use them without wholesale deletion or commenting out of parts of the configuration file.
In the initialization code, you will then do something like,
// find number of structures int num_values = config->numValues("structures"); // get the structure names const char** structures = new const char*[num_values]; config->getStrings("structures", num_values, structures); for (int i=0; i<num_values; i++) { utils::ConfigFile structure; // get a structure if (config->getStruct(structures[i], structure)) { initialize_something(structures[i], structure); } else { // not finding a structure is a fatal error cerr << "Unknown structure " << structures[i] << endl; return false; } } // clean up the structure names delete [] structures;
This approach maximizes the flexibility of reading in multiple structures while minimizing the effort of the module developer when it comes time to tweak which structures are read in what order.
The ModUtils configuration file system addresses these needs as follows:
%include other_file.cfg
int current = $previous;
int $previous = 50;
struct foo { int bar = 1; } struct bletch = $foo;
bletch to struct bletch { int bar = 1; }
In addition, you can add to structures instead of overriding them through the mergeStruct primitive, so given the above examples,
mergeStruct foo {
string s = "hello";
}
struct foo { int bar = 1; string s = "hello"; }
Thus, you can have a core configuration file with all of the most common parameters and specifications made in it. Then, for a specific configuration you can include this file and then modify elements in it to adapt for the specific setup you need.
A good example is that your system integrator should maintain a calibration.cfg file for all geometric relationships for a given vehicle. In your configuration file you would use it something like this,
%include calibration.cfg struct scanner_pose = $Calibration.LeftSick; double left_side = $Calibration.Vehicle.left;
Thus, if the calibration of the sensors changes it will automatically be propagated to all files that include calibration.cfg. In addition, your system integrator could take advantage of the way directories are searched for configuration files by putting the calibration.cfg in $LOCAL_CONFIG_DIR. Then, if you switch vehicles, you just change the environment variable $LOCAL_CONFIG_DIR, and you then read in the appropriate calibration.cfg for that vehicle.
Another example of good practice is that as your module matures, you will want to split out the algorithm specific parameters into a separate file from the specifications of interfaces and calibration information.
%include calibration.cfg # parameters for setting up module and interfaces bool exit_on_no_data = false; spec scanner_spec {player: name=mydata.rad; } # include algorithm specific parameters %include mymodule_params.cfg
When it comes time to integrate your code into the larger system, this will mean that the system integrator can just include your algorithm parameters from the file mymodule_params.cfg and can set the calibration and specification parameters separately and cleanly.
include directives and variables within configuration files there can be a lot of confusion about what is being read from where.
The first level of debugging is to set the CONFIG_VERBOSE environment variable to 1. I you do this then you will get output which details the full path of every read configuration file. This will help you determine if the path search environment variables are correct.
For example, when we set CONFIG_VERBOSE to 1 and run this program, we get the following output,
> ./datmomod
ConfigFile: Opening ././datmomod.cfg
Including /home/jayg/PennDOT_SCWS/config/calibration.cfg
Including /home/jayg/PennDOT_SCWS/config/filenames_II.cfg
Including /home/jayg/PennDOT_SCWS/config/vehicle_params_pat.cfg
Including ./datmo.cfg
.
.
Meaning we first read in datmomod.cfg which goes on to read calibration.cfg and datmo.cfg. calibration.cfg itself reads two other configuration files. As you can see, this level of configuration verbosity can be very useful at almost any time.
The next level of debugging is to set the CONFIG_VERBOSE environment variable to 2. If you do this then you will get output which details exactly what variables are read, the values that are returned, and whether or not those values came from the default or from the configuration file or not.
For example, in the above example if we set CONFIG_VERBOSE to 2, we get
> ./datmomod ConfigFile: get tag = "active" ConfigFile: get name = ./datmomod.cfg ConfigFile: Opening ././datmomod.cfg Including /home/jayg/PennDOT_SCWS/config/calibration.cfg Including /home/jayg/PennDOT_SCWS/config/filenames_II.cfg Including /home/jayg/PennDOT_SCWS/config/vehicle_params_pat.cfg Including ./datmo.cfg ConfigFile: get default running = 1 ConfigFile: get default paused = 0 ConfigFile: get display = true ConfigFile: get default idle_time = 0.1000000 ConfigFile: get default display_interval = 0.0333000 ConfigFile: get time_source_spec = { driven : } ConfigFile: get tag = "driven" ConfigFile: get default exclusive = 1 . .
Plus a whole lot more, as this was truncated for space. Here you see debugging output whenever any part of your code executes a get command. For example, the idle_time query returns a default of 0.1, while the display query reads true from the file. This option is useful when you are very confused about what your system is reading. It is especially good at catching mispellings of parameters, as if you mispell a parameter in either the code or the configuration file, you will end up reading the default value when you expect the value to be set in the file.
ConfigSource is for more than just acquisition of parameters during initialization. In an integrated, live situation, it serves as a generic means for a module to interact with the system and system management processes.
First, in a live situation, the configuration source can be considered an active database, not just something that is read and never changes. One way to put "hooks" into your module to allow it to be controlled by the system is to use attach methods for obtaining configuration information instead of get methods.
The attach methods look very much like the get methods, except instead of returning a value they modify the memory you pass in. In this example we attach to the variable foo. When it is changed in the central database, this change is propagated to the module and _foo is modified with the new value. This allows changes in the central database to be propagated to the module.
// attach to foo with a default value of 5 config->attachInt("foo", 5, &_foo);
This mechanism is how the running and paused magic variables described in the module life cycle really work. In the central database, each module has a corresponding structure.
struct Modules { struct MyModule { bool running = true; } }
where running is set to true to indicate the module is active. As part of a module's (say it is named MyModule) initialization, it essentially does a
config->attachInt("Modules.MyModule.running", true, &_running);
When the process manager wants to shut down MyModule cleanly, it sets Modules.MyModule.running to false, which gets propagated to MyModule. The change of _running from true to false causes the module life cycle to gracefully come to an end, and the module exits.
One thing you may find is that you need to be notified immediately if a parameter changes. This could be because your module needs to recompute some other internal parameters things based on the new incoming parameter changes. If this is the case, you can pass in a function pointer that gets invoked when the parameter changes. In order to have the callback be a member function of your module, you tend to have to do something like
class MyModule { private: // you need a static member function to give to the callback static static_cb(const char* name, utils::Type type, void* data, int num_elems, void* cbdata) { // a pointer to the module class instance is passed in cbdata ((MyModule*) cbdata)->member_cb(name, type, data, num_elems) } // the actual callback, which takes the name of the // parameter changed, its type, and the raw data void member_cb(const char* name, utils::Type type, void* data, int num_elems) { } . . }; bool MyModule::initialize(ConfigSource* config, utils::SymbolTable* globals) { . . // attach to a variable, and ultimately invoke member_cb when it is changed // (note we pass in static_cb and set the callback data to this attachInt("foo", 5, &_foo, static_cb, this); . .
If you can, in your run method, produce a 10-30 character description of what is going on, and register it. For example, in an object tracking application you might do the following,
char msg[200]; snprintf(msg, 200, "%d objects found", num_objects); getConfigSource()->setStatusMessage(msg);
There are also two floating point numbers you can set, the status and the confidence. The exact meaning of these numbers is not currently set, so you can assign whatever meaning you want to them at this time. In the run method, you might do,
getConfigSource()->setStatus(1.0); getConfigSource()->setConfidence(1.0);
Although these are undefined, it is recommended that you use status to indicate how far along any particular task your module is (for example, percentage path completed in a path tracker) and use confidence as a measure of confidence of the output (for example, for a road follower, percentage of certainty that there really is a road in front of the camera).
The more information you put into your status reporting, the easier it will be to debug the system. The system integrator can view a summary of all the status reports simultaneously, so every little bit helps when trying to fix a system.
Module is is TimeSource. The module developer will hardly ever use the time source directly, but behind the scenes it provides an abstract interface to the flow of time. This abstract interface to time is one of the keys in allowing modules to work both with canned data and in real time with real data. In real time, the time source is simply connected to the system clock. When replaying data, the time source can be manipulated in a variety of ways to make sure different interfaces are accessing canned data from the same time.
If you need the current time in your module, include TimeSource/TimeSource.h and use the call
utils::Time cur_time = TimeSource::now();
A word of advice: If you find yourself using this call you are probably doing something wrong. In general, time should be driven by your data sources rather than read directly from a clock.
TimeSource::now method, you will be using time derived from data often. ModUtils provides a specialized time class, utils::Time to store and manipulate time.
The most useful operations with utils::Time are
utils::Time t1(21, 500000); // 21.5 seconds utils::Time t2(21.5); // ditto
utils::Time a, b, c, d; c = a+b; d = a-b;
utils::Time t; double double_t = (double) t;
utils::Time that you will commonly see in module code is getting the time of day with utils::Time::getRealTimeOfDay: This is simply a cover for the system clock call. Remember not to use utils::Time::getTimeOfDay as the result can be sped up, slowed down, and paused by the utils time source. The usual use for utils::Time::getRealTimeOfDay is to calculate the elapsed time for an operation.
utils::Time prev = utils::Time::getRealTimeOfDay(); ... // do something utils::Time cur = utils::Time::getRealTimeOfDay(); double elapsed = (double) (cur - prev);
spec scanner_spec {lms:
resolution = 0.5;
port = /dev/ttyS5;
}
struct scanner_spec { string tag = "lms"; resolution = 0.5; port = /dev/ttyS5; }
tag will be the interface tag, i.e., which of the suite of interface instances we are selecting, and the remaining parameters are used to parameterize the selected interface instance.
So, the spec <name> {<tag>: ... } idiom is an extremely common convenience expression for building reconfigurable interface specifications. For further convenience if you want to specify an interface tag and use all of the parameter defaults, you can use
spec scanner_spec = lms;
spec scanner_spec {lms: }
Nested specifications
Typically, a nested specification will use the tag contained, e.g.,
spec scanner_spec {logger:
spec contained {lms:
port=/dev/sick1;
}
string name=LeftSick.raw;
}
In this example, the logger interface contains a lms interface. The idea is that we read data from the sensor, log it to the file LeftSick.raw, and then pass it on to the user without the user knowing the data has been tapped.
./foo "iptclient: module_name='foo';"
starts the module foo with a configuration source of type iptclient and with the module_name parameter set to foo. Now, if the command line argument is an existing file, it gets converted into the appropriate specification, so if you type
./foo foo.cfg
and foo.cfg exists, it gets converted into
./foo "active: name=foo.cfg;"
As a module developer, you will not have to worry about this too much. You can go on assuming that what you type in at the command line of a module is just a file name. This facility is mainly to provide hooks so that the process management system can start up the module with a completely specified configuration source that hooks up to the central database instead of directly to a file. The one reason you will have to know about this is to understand why a module fails with an "invalid configuration" error: If you enter a file that doesn't exist in any searched directory that filename will be parsed as a specification string, which will result in a cryptic syntax error like this,
> ./datmomod hoopla.cfg Line 1, error 'Can not find structure 'hoopla'', buffer 'hoopla.cfg' Module: Invalid spec 'hoopla.cfg'
Module class always looks for the variable time_source_spec in the configuration source and uses it to create a time source. It defaults to default, which is a synonym for utils, i.e.
spec time_source_spec = unix; # these two
spec time_source_spec = default; # are equivalent
This default time source simply uses the utils::Time::getTimeOfDay static method to read the system clock, although it can be tweaked to make time move faster or slower with the scale parameter:
spec time_source_spec {utils:
float scale = 0.5; # time moves at 1/2 speed
}
There is actually a large variety of time source interface instances. In addition to the utils tag, there are also currently
driven: Reading data drives time.sim: Initial time is set by data and then advances with the system clock.gui: Same as sim, but managed by a GUI to allow interactive time setting.shmemPublish: Publishes time over the network. You might use his if you were running multiple modules running in simulation or on canned data, but still communicating via the network, and you wanted one module to drive time for the others.shmem: Time is set by another module using a shmemPublish time source.initialize method. The preferred way to instantiate an interface is to use the templated Module method, create:
const char* spec=config->getString("scanner_spec"); _scanner = create<LineScanner>(spec); if (!_scanner) { fprintf(stderr, "Bad scanner spec '%s'\n", spec); return false; }
The create method is templatized by the reconfigurable interface class type, in this case LineScanner and, if successful, returns a pointer to the newly minted interface of that type. The parameter spec is the scanner_spec specification read in as a string. The create method returns NULL on failure, and you should check its result to avoid core dumps. Often interfaces are "required," as shown in this example, and a failure to create them properly should cause the initialize method to exit with false, which, ultimately, causes the module to exit. Sometimes you will just want to print a warning and move on, although you will then need to check the interface to make sure it is non-NULL everytime you want to use it. You will want to store the result in a class member variable, such as _scanner, to keep the interface accessible by the run method even though it was created in the initialize method.
You do not have to worry about memory management with a reconfigurable interface created by the create templatized method. If you use this method to create an interface, the Module class will take care of the memory management bookkeeping. When your Module instance gets destroyed at the end of the module life cycle, it will take care of deleting (and thus closing down and cleaning up) all interfaces created with the templated create method.
The reconfigurable interface plug-ins are dynamically loadable library in a particular location with a particular name containing a particular creation function. For example, given a VehPose interface and a interface instance named logger, the system will look for a dynamically loadable library named VehPose/logger.so. Note that this is a relative path. Reconfigurable interface plug-ins are searched searched for in the directories defined by the following environment variables in the following order:
$PROJECT_INTERFACE_DIR $INTERFACE_DIR $INTERFACE_LD_PATH with a list of colon separated directories, then the system will search for plug-ins by class and tag name in those directories and ignore all of the other environment variables.
Normal usage is to just set the directory $INTERFACE_DIR appropriately.
If there is a problem in finding the interface plug-in, the interface generation system will tell you, printing out all the places it thinks it should look. If the interface plug-in is found, but cannot be loaded, this is normally because of missing symbols in the interface plug-in. The generation system will print out the absolute path to the plug-in that is missing a symbol as well as the missing symbol. Note that the missing symbol will almost certainly be a mangled C++ name with many apparently random letters and numbers inserted. The cause of this is usually the interface implementer forgetting to include a necessary library on the linking line that created the shared interface plug-in.
With dynamically loadable plug-ins, it can be difficult to know exactly what version of the code is being used. To address this we introduced the $INTF_VERBOSE environment variable. If this environment variable is defined to 1 then when a properly defined interface's creation function (i.e., one that uses the UTILS_INTF_REPORT macro) is invoked, it will print out information derived from the source control system on the version that is being used (currently this only works with subversion). If $INTF_VERBOSE is defined to 2, then a properly defined interface's creation function will print out additional information about the building system taken at the time the interface plug-in was compiled.
As a module developer, the most important pattern for you to understand is the data replay instance tagged with player. Since flexible data replay is at the heart of successful robot algorithm development, almost any data source interface class will have a player instance, and they are usually implemented using the commong utils::Player facilities, meaning they should work the same across all the reconfigurable interface classes.
When the index and data file is combined, we usually us a .rad (Random Access Data) extension. When they are separate, we use a .raw extension for the index file and a .raw.data.0 extension for the data file.
There are a variety of generic utilities you can use to play around with canned data:
cddescribe filename cdcrunch input output cdshift filename offset output cdexcist input start length output length seconds of data starting at start seconds from the start of the file.player. The options for a player interface are read in by the utils::Player class, so they should be standard across all data replay interfaces.
The most important option is the name of the data file, which is set by the string parameter name.
string name = datafile.rad;
DATA_DIR search directory is first, so we will look for data before configuration files, and, as a side effect, and put data-specific configuration files in the data directory and have them override the normal configuration files. A typical usage is to cache the calibration.cfg file (see the configuration file usage example) used when collecting an important data set with the data set itself, so when we point DATA_DIR to the data set's directory we end up using the correct calibration file which encodes where the various sensors were pointed for that data set.The key to the data replay interface is that it can be configured to interact heavily with the time sources, allowing two common modes:
A third mode is to "ignore time," i.e., just sequentially read data from the file without any connection to a time source either before or after reading.
To use this mode, you have to put the following in your configuration file to tell the Module class to use a driven time source
spec time_source_spec = driven;
Then, for your primary data source, you pass in
bool drive_time=true;
player specification. If you want you can seek into the file with the offset parameter. For example, double offset=30.0;
bool real_time=true;
player specification to sleep between reading elements for approximately the correct time. Since, at least for Linux, the granularity of sleeping is at best 10ms, this will not be exact, but can be used to "slow down" your system to approximately real time when running, if necessary.
For all other player data sources, you pass in
bool drive_time=false;
player will examine the current time, and will return the data nearest to but preceding the current time.
A complete file for a typical debugging setup will look something like this in a file we will call module.cfg,
# data will drive time spec time_source_spec = driven; spec main_scanner_spec {player: string name = FrontSick.rad; bool drive_time = true; # the default, BTW float offset = 100.0; # start 100 seconds in } spec secondary_scanner_spec {player: string name = BackSick.rad; bool drive_time=true; }
gui time source and properly configured data sources to quickly zoom around the whole data set using a simple GUI.
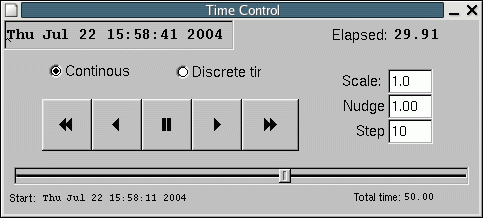
Time Control GUI
To use the gui time source for replay, I suggest you include the driven configuration file to use as your base, and then override the time source to be
spec time_source_spec=gui;
bool drive_time=false; # driven by GUI instead of drive time bool set_time=true;
set_time parameter is used to tell the GUI timesource that the extent of time (its beginning and end) is defined by this data source. You can use this parameter in all of the data sources if you wish, and the extent of time will simply go from the earliest beginning to the latest ending.
A complete configuration file, named, for example, replay.cfg would look something like,
%include module.cfg # GUI will drive time, after being initialized by data spec time_source_spec = gui; # override main spec main_scanner_spec {player: string name = FrontSick.rad; bool drive_time=true; bool set_time = true; } # all other data sources already defined properly # in module.cfg
A typical usage would be to use the replay.cfg configuration to find interesting parts of the data and make note of the elapsed time. Then you use the default configuration with the appropriate offset values to reliably debug those interesting parts. Finally, you can use replay.cfg to do some final verification before live testing.
Some words of warning:
utils::Time::sleep at the end of the run. Setting this parameter (which currently is not standardized as a part of the Module class and so can vary from module to module) to non-zero when in replay mode can be necessary to avoid overloading the processor.ignore_time to true in the player specification and that interface will just read through the file sequentially without adjusting position for the current time or setting the current time from the data file.utils::Vec3d (stands for a vector of length 3 of double precision floating point numbers).
Instances of utils::Vec3d are constructed by default as all 0's, or they can be passed the axis values. You can then access them by axis or index, i.e.,
utils::Vec3d v(1.0, 2.0, 3.0); double x,y,z; x=v[0]=v.x; y=v[1]=v.y; double z=v[2]=v.z;
There are many other common operations which might be useful to you.
double l = v.length(); // calculate length utils::Vec3d n = v.normalize(); // normalize utils::Vec3d s = n + v; // addition utils::Vec3d d = n - v; // subtraction v *= 3.0; // scalar multiplication v /= 3.0; // scalar division double prod = v.dot(n); // dot product utils::Vec3d p = v.cross(n); //cross product
utils::Transform. A 3D homogeneous transform is simply a 4x4 matrix with the following structure,
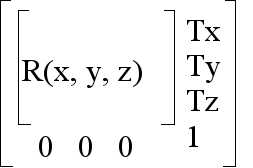
Homogeneous transform matrix
The most important thing you can do with a homoegeneous transform is apply them to 3D points via multiplication.
utils::Transform t; utils::Vec3d pt1,pt2; . . pt2 = t*pt1;
t to pt1, resulting in pt2.You can compound transforms via multiplication from right to left.
t_ac = t_ab * t_bc;
By default, utils::Transform instances are constructed as identity matrices, i.e., the null transform. You can also build them out of translations and rotations.
utils::Transform t(utils::Vec3d(100, 0, -5),
utils::Rotation(0.0, 0.0, M_PI/2.0));
Other useful methods include,
utils::Transform i = t.inverse(); // invert a transform t.equals(p, 0.001); // equality within tolerance t.multMatrixDir(pt, res_pt); // apply just the rotation to a point
Since homogeneous transforms are fundamental parts of many robotic systems, we have built-in support for specifying them. On the code side you would do something like this,
utils::ConfigFile transform_struct; utils::Transform transform; if (config->getStruct("scanner_transform", transform_struct)) transform.set(transform_struct)
In the corresponding configuration file, you can use the full 4x4 matrix, like this,
struct scanner_transform { double values[16] = 0.0 0.0 1.0 3.1 1.0 0.0 0.0 0.9 0.0 -1.0 0.0 0.0 0.0 0.0 0.0 1.0; }
Alternatively, you can use more human friendly formats in the configuration file, such as,
struct scanner_transform { struct rotation { double axis[3] = 0 0 1; // around z axis double angle = 1.0; // rotate by 1 radian } double translation[3] = 1.33 0 -1.92; // x, y, z translation }
utils::Rotation instances are constructed as a rotation by an angle around a 3D axis,
// Rotate 1 radian around z axis
utils::Rotation r(utils::Vec3d(0, 0, 1), 1.0)
For convenience, you can also construct a rotation by its Euler angles, i.e., roll pitch and yaw.
utils::Rotation r(roll, pitch, yaw);
The default constructor for utils::Rotation is the identity rotation. Some useful methods you might see include,
utils::Rotation r; utils::Vec3d pt2 = r*pt; // apply to a vector utils::Rotation r3 = r2*r1; // compound, from right to left utils::Rotation i = r.inverse(); // invert a rotation utils::Rotation::slerp(r1, r2, t); // interpolate between rotations r.equals(r2, 0.001); // equality with a tolerance in radians
utils::Vector template class. It is simply an abstract, templated variable sized vector class. In most situations you should use the STL template std::vector, but you may see it used in many legacy interfaces and applications.
Because of its simplistic implementation, it can only be used for structures with no constructors (or with pointers), but it still has some uses which prevent its being completely replaced by the STL vector class. The primary advantage it has is its very simplicty: utils::Vector explicitly represents its storage as a contiguous block of data while std::vector completely hides its implementation. This means you can build up a utils::Vector and then access the whole stored vector with a pointer, making it much more efficient if what you want to end up with is a contiguous block of data for writing to disk or sending across a network.
The main things you will need to know is that you can access elements using indices and get the size of the vector with the numElems method.
utils::Vector<double> v; for (int i=0; i<v.numElems(); i++) double d = v[i]
Some other useful methods you might see are,
v.append(3.0); // append an element v.prepend(1.0); // prepend an element double* data = v.getData(); // get data area v.clear(); // clear out vector v.insert(3.0, 1); // insert 3.0 at index 1 int index = v.find(3); // find 3 in list return index, or -1 if not there
 1.4.4
1.4.4